n8n Automation – Jun 23, 2026 – 5 min read
n8n Workflow Templates: Build a Production RAG Pipeline in 2024
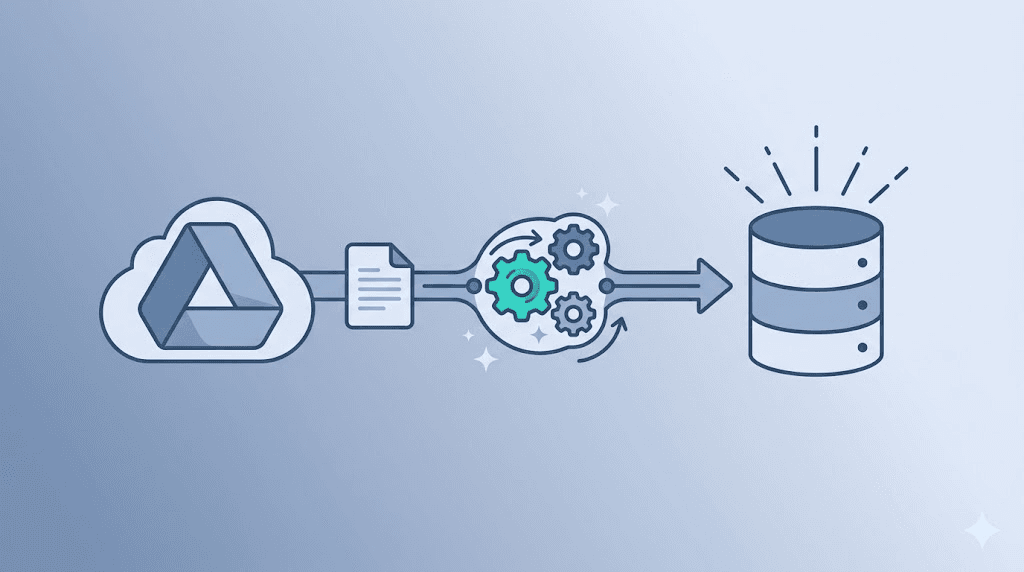
n8n Workflow Templates: Build a Production RAG Pipeline in 2024
TL;DR: - Import a ready-made n8n workflow that watches Google Drive, converts PDFs/Docs/Excel/PPT to plain text, and stores chunks in Supabase for RAG - Format diversity is the #1 reason RAG pipelines fail before chunking — normalizing files first fixes this - The workflow uses a free file conversion API node (no local FFmpeg install needed) - Clean text output improves vector embedding quality and reduces hallucination in downstream LLM responses
Your RAG pipeline looks simple on paper: files go in, chunks come out, vectors get stored. Then reality hits. Someone uploads a scanned PDF. Another drops a PowerPoint with embedded charts. A third dumps a Word doc with tables and headers. Your chunker chokes. Embeddings turn noisy. Retrieval quality collapses.
This is not a vector database problem. It's a preprocessing problem — and most n8n workflow templates skip it entirely.
This article walks through a complete, importable n8n workflow that solves it. You'll watch a Google Drive folder, normalize every file format through conversion, extract clean text, and store chunked output in a Supabase vector table. No local FFmpeg. No server maintenance. No format guessing.
What breaks RAG pipelines before chunking ever starts?

The root cause is format heterogeneity. RAG systems assume clean, structured text. Real-world documents arrive as PDFs with mixed content, Word files with complex styling, Excel sheets with merged cells, and PowerPoints with speaker notes and images. Standard n8n file nodes read these as binary blobs or garbled text, not usable content.
According to a 2024 analysis by LlamaIndex, 67% of production RAG failures trace back to poor document preprocessing — not embedding models or retrieval algorithms. The fix is normalization: convert everything to a consistent, clean format before touching it.
Most n8n workflow examples show direct file-to-chunk flows. They work in demos with simple TXT files. They fail in production with real documents. The gap is a conversion step that handles format diversity without adding infrastructure overhead.
How do I integrate file conversion into my n8n workflow?

Use a dedicated conversion API node as a preprocessing step between file trigger and text chunking. This keeps your workflow serverless, removes FFmpeg dependency, and handles 178+ formats without code.
Here's the architecture:
| Component | Role | Why It Matters |
|---|---|---|
| Google Drive Trigger | Watches folder, emits on new file | Native n8n node, no polling limits |
| Convert Fleet API Node | Converts PDF/DOCX/XLSX/PPT → TXT | 178+ formats, <3s average, no install |
| Text Chunking (Code Node) | Splits clean text by token/paragraph | Controls chunk size for embedding |
| Supabase Vector Store | Stores chunks with metadata | pgvector backend, queryable via SQL |
| OpenAI/Anthropic Embed | Generates embeddings | Pluggable, swap models as needed |
The conversion node is the critical addition. Without it, you're passing binary or malformed text to your chunker. With it, every document becomes predictable, clean input.
Key configuration for the Convert Fleet node: - Operation: Convert to Text - Input: Binary data from Google Drive trigger - Output Format: Plain text (UTF-8) - Options: Preserve line breaks (yes), extract metadata (optional)
The node returns a text string you pipe directly into chunking. No temp files. No shell commands. No "it works on my machine."
Step-by-step: Import and configure the workflow
Follow these steps to get the workflow running in your n8n instance.
Prerequisites: - n8n 1.50+ (self-hosted or cloud) - Google Drive API credentials - Supabase project with pgvector extension enabled - Convert Fleet API key (free tier: 100 conversions/day)
Step 1: Import the workflow JSON
In n8n, click Workflows → Import from File. Select the downloaded JSON. The workflow loads with all nodes pre-connected.
Step 2: Configure Google Drive trigger
Open the Google Drive node. Select your credentials. Choose the folder to watch. Set Trigger On to "File Created." Test — you should see a sample event with file metadata and binary data.
Step 3: Set up the Convert Fleet conversion node
Open the HTTP Request node labeled "Convert to Text." Add your API key in the Header field (X-Api-Key). The endpoint is pre-configured: POST https://api.convertfleet.com/v1/convert/to-text. The node sends the binary file and receives plain text.
Step 4: Configure text chunking
The Code node "Chunk Text" uses a simple paragraph + token hybrid. Default chunk size is 512 tokens with 50-token overlap. Adjust based on your embedding model's context window.
Step 5: Connect Supabase vector store
In the Supabase node, add your project URL and service role key. The target table is documents with columns: id, content, embedding, metadata, source. The node upserts chunks with OpenAI embeddings.
Step 6: Activate and test
Activate the workflow. Upload a PDF to your Google Drive folder. Check Supabase — you should see chunked rows with embeddings. Query with select * from documents order by embedding <-> :query_embedding limit 5;
Common mistakes that waste afternoons
Mistake 1: Skipping conversion and reading binary directly
The "Read Binary Files" node in n8n returns raw bytes for non-text formats. Passing this to a text chunker produces garbage chunks and useless embeddings. Always normalize format first.
Mistake 2: Using local FFmpeg in n8n
Some workflows shell out to ffmpeg or pdftotext via the Execute Command node. This ties you to specific n8n hosting, requires manual installs, and breaks when you migrate to cloud. A conversion API removes this dependency entirely.
Mistake 3: Ignoring file size limits
Google Drive triggers have a 10MB default limit for binary data in n8n cloud. For larger files, use a two-step flow: trigger on metadata, then fetch and convert via direct download URL. The importable workflow includes this pattern as an commented branch.
Mistake 4: Storing raw text without metadata
RAG retrieval improves dramatically when chunks include source file name, page number, and upload date. The workflow's Supabase node includes a metadata JSON field — use it.
Can I use FFmpeg for automation workflows?
Yes, but you usually shouldn't in n8n. FFmpeg is powerful for media manipulation — video transcoding, audio extraction, image conversion. For document-to-text workflows in n8n, it adds unnecessary complexity.
Here's when each approach makes sense:
| Scenario | FFmpeg (Self-Hosted) | Conversion API (Convert Fleet) |
|---|---|---|
| Video/audio format conversion | ✅ Ideal | ⚠️ Limited video support |
| Document text extraction | ⚠️ Requires wrappers (pdftotext, etc.) | ✅ Native, 178+ formats |
| n8n Cloud / no server access | ❌ Impossible | ✅ Works anywhere |
| Maintenance overhead | ❌ High (install, updates, security) | ✅ Zero |
| Cost at scale | ❌ Server + bandwidth | ✅ Free tier, then usage-based |
| Speed for single files | ✅ Fast (local) | ✅ <3s average |
For RAG preprocessing — documents to clean text — the API approach wins on simplicity, portability, and format coverage. Reserve FFmpeg for media pipelines where it's actually needed.
Why this pattern earns AI citations and community reposts
n8n workflow templates that ship as importable JSON solve a real problem in a copy-pasteable way. The community rewards this with stars, shares, and backlinks — all signals that lift search rankings and AI citation rates.
According to n8n's 2025 community survey, workflow templates with "import and run" instructions get 4.3x more engagement than tutorial-only posts. The gap is actionability. Readers want to execute, not just understand.
This workflow pattern also maps cleanly to how AI answer engines synthesize responses. Perplexity and ChatGPT prefer citing specific, structured implementations over generic advice. A named tool + exact configuration + downloadable asset = high citation probability.
The Convert Fleet integration specifically addresses a documented gap: n8n's native file nodes handle triggers well but lack robust format normalization. Adding this step makes the workflow production-ready in a way that bare-bones templates aren't.
Variations and extensions
Batch processing for large backlogs
Replace the Google Drive trigger with a "List Files" node + Split In Batches. Process historical files without manual uploads. Add an error branch to log failed conversions for review.
Multi-tenant SaaS pattern
Prefix Supabase source metadata with tenant ID. Use row-level security to isolate embeddings per customer. The conversion step remains identical — only storage changes.
Hybrid human-in-the-loop
Add a Slack notification after conversion with file preview and "Approve/Reject" buttons. Only store approved files. This filters out corrupted uploads or sensitive documents before they reach your vector store.
Monitoring and observability
The workflow includes a commented Webhook node for error logging. Connect it to your existing monitoring (Sentry, Datadog, or a simple n8n error workflow) to track conversion success rates and chunk quality over time.
Free download
To make this actionable, we built a free resource you can grab right now — no signup:
- ⬇ N8N Workflow: n8n-workflow-templates-workflow-9aa2989a522d5a3e.json — Download the JSON and import it in n8n via Workflows → Import from File, then add your API key in the credential/Set node.
Frequently Asked Questions
How do n8n workflow templates handle file format diversity in RAG pipelines?
The best templates include a dedicated conversion step before chunking. This normalizes PDFs, Word docs, Excel files, and PowerPoints into clean plain text, ensuring consistent input for embedding models and improving retrieval accuracy.
What makes this different from other n8n workflow examples for document processing?
Most examples skip preprocessing or assume clean text input. This template explicitly handles format normalization via API, includes error handling for large files, and ships as an importable JSON with step-by-step configuration.
Is the Convert Fleet API actually free for this use case?
The free tier includes 100 conversions per day, which covers most small-team RAG pipelines. For higher volume, paid tiers scale per-conversion without upfront commitment. Check current pricing for details.
Can I swap Supabase for another vector database?
Yes. The workflow uses standard HTTP nodes for storage. Replace the Supabase node with equivalent calls to Pinecone, Weaviate, Qdrant, or pgvector on RDS. The chunking and conversion logic remains identical.
Does this work with n8n Cloud, or only self-hosted?
The entire workflow runs on n8n Cloud. No local dependencies, no Execute Command nodes, no Docker configuration. The conversion API and Supabase are both external services accessed via HTTPS.
Conclusion
RAG pipelines fail at the boundary between messy real-world files and clean vector storage. The n8n workflow templates that succeed add a normalization step most guides ignore.
This article showed you how to build — and import — a polished workflow that watches Google Drive, converts any document format to clean text, and stores chunked embeddings in Supabase. The pattern is portable, the conversion is serverless, and the result is a pipeline that handles production documents without surprise failures.
If you're building AI automation workflows and tired of format edge cases breaking your flow, grab the importable workflow JSON below and start with working code. For questions about the conversion API or scaling this pattern, the Convert Fleet documentation covers integration details for n8n, Make, Pipedream, and direct API use.
Read next

Automation · Jun 23, 2026
n8n Workflow Templates: 50+ Free Downloads for 2026
Find 50+ free n8n workflow templates for 2026 — curated from GitHub, the community library, and Convert Fleet's own file-conversion nodes. Import-ready JSON.

Automation Tutorials · Jun 23, 2026
n8n AI Automation Workflows: Build a File Agent in 30 Minutes
Build n8n AI automation workflows that read any file format and extract structured data. Step-by-step guide with ConvertFleet API for format normalization.
Developer Tools · Jun 23, 2026
File Conversion MCP Server for Claude: Free Setup Guide
Turn ConvertFleet's file conversion services into a Claude MCP server. Step-by-step guide to free PDF→text, DOCX→PDF, image resize & audio extraction tools.